
When to Use Sequences
One of the most common questions I get about Kotlin’s sequences is this:
“When should I use sequences, and when should I use normal collections?”
That’s the question we’re going to answer in this third and final article in this series! We’re going to look at the trade-offs of each, including the main things that affect their performance. Then, we’ll look at how Kotlin’s sequences stack up against Java streams, a similar concept.

If you’re asking yourself what a sequence is, you should definitely read the first article in this series, Kotlin Sequences: An Illustrated Guide. And if you’re looking to understand exactly how they’re implemented, you should take a look at the second article, Inside Kotlin Sequences.
All caught up? Great - let’s go!
Sequences vs. Collections: Performance
Performance is tricky business. Yes, sequences are known for their performance benefits over standard collection operations. But there are certain characteristics that can totally blindside you if you’re not aware of them. In fact, in many cases, collections can be more efficient than sequences!
There are a few main factors that can affect performance. It’s helpful to think of these factors as weights on a scale - some factors will tend to tip the scales in favor of sequences, and some will tend to tip the scales in favor of collections.

Knowing these factors - and how they combine - can be a helpful starting point for understanding when sequences might be a better choice than collections. Keep in mind that multiple factors often will be in play at one time - one factor will tip the scales in one direction, but the next factor might tip it farther in the other direction.
Also, it’s critical to understand that unless you actually run benchmarks on your specific code with true-to-life data, you can’t know for sure. So keep that in mind as we explore these factors!
Factor #1: Operation Count
As you know, collection and sequence operations such as filter(), map(), and take() can be linked together into an operation chain, like this:

You might recall that collection operations chains create an intermediate collection in between the operations:

Sequence operation chains, on the other hand, do not have a need to create these intermediate collections.
The more operations you have in your chain, the more intermediate collections would be created if you were to use a collection chain. So if you’ve got an operation chain with many operations in it, a sequence would often be a better choice.
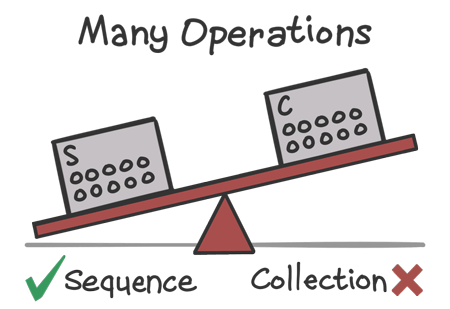
Keep in mind, though, that it’s not just the number of operations that matters. The kinds of operations can also have an incredible impact on performance! Let’s look at some examples.
Factor #2: Short-Circuiting Operations
As you might recall, one of the main differences between sequences and collections is the order that each operation is applied to each individual element. Here’s a diagram from the first article in this series, which compares how the individual elements are processed for a simple filter { ... }.map { ... }.take(5).toSet() chain, for both a collection and sequence.
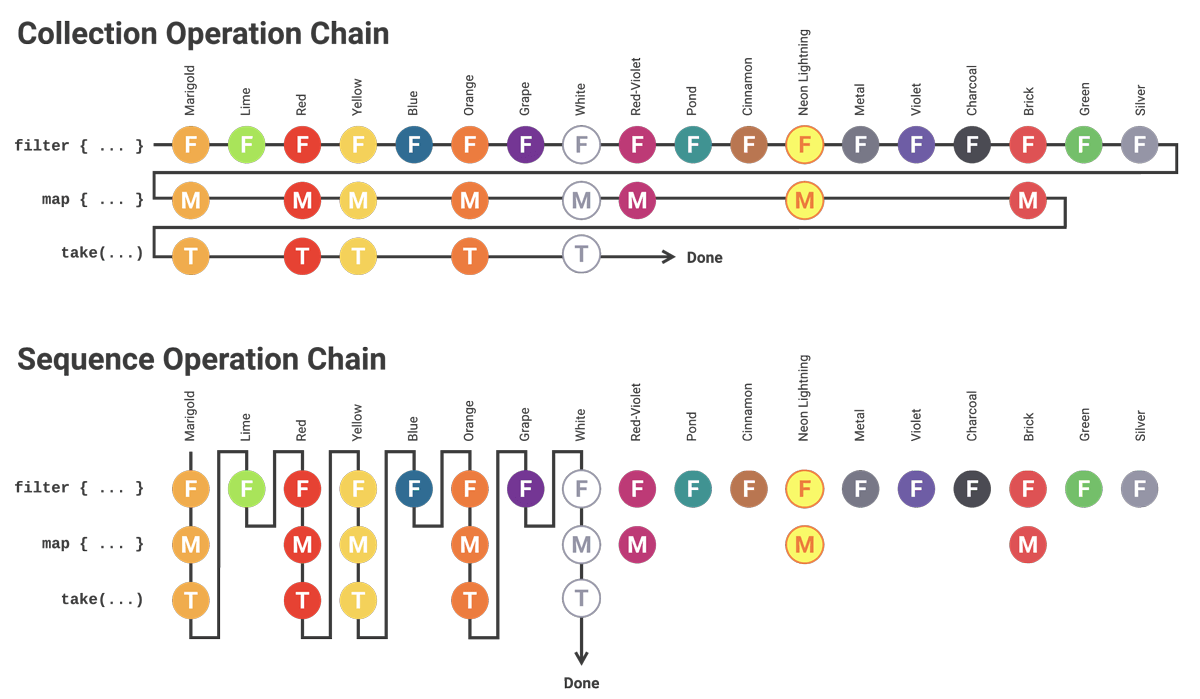
Because this chain included take(5), the sequence version was able to quit after executing just 18 operations, when it encountered it’s fifth element. Contrast that with the collection version above, which produced the same output but had to execute 31 operations to get there.
The take() function is what we might call a short-circuiting operation, because it can stop processing items once some condition has been met.
There are plenty of other short-circuiting operations, such as:
contains()andindexOf()- Once the element is located, there’s no need to continue iterating.any(),none(), andfind()- Similarly, once an element that matches the predicate is found, there’s no need to iterate further.first()- Naturally, this one can short-circuit after it gets the very first element.
These functions will usually tip the scales in favor of sequences, especially in cases where you’ve got:
- many operations,
- many elements, and…
- the matching element appears toward the beginning.
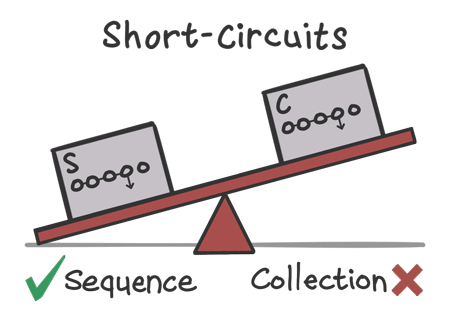
Factor #3: Resizable Collections
So far, we’ve seen cases where sequences can really shine - when there are lots of operations, or when they can short-circuit. But certain operations use resizable collections, and they can drastically tip the scales back toward collections. If you don’t know to look for them, they can really catch you off guard. Let’s dig in!
Collecting Results
Often, when you’re done with all of the processing steps of a sequence, you’ll want to collect the results into a list or a set. For example:
val shades = colors .asSequence() .map { it.toGrayscale() } .toList()In this code, once the colors have been mapped to grayscale, the resulting grayscale values are collected into an
ArrayList.As you might recall, an
ArrayListon the JVM stores its items using a regular Java array under the hood.These arrays have a fixed size. In other words, when you create the array, you choose the size, and that’s how many elements it can hold, forever and ever. You cannot increase the size of an array. The
ArrayList, however, can grow in size.So how does that work?
When you create a new
ArrayList, it has an initial capacity - that is, the size of the underlying array that it uses. You can tell it what capacity to use when you call its constructor, or it can go with its default, which is ten.So let’s say we have an
ArrayListwith an initial capacity of ten, so its underlying array has ten slots: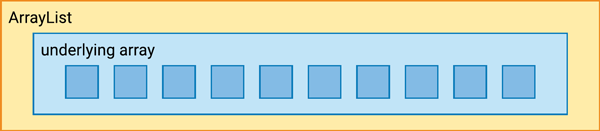
We can
add()ten items, and each is inserted into the underlying array. But what happens when we want to add an eleventh item?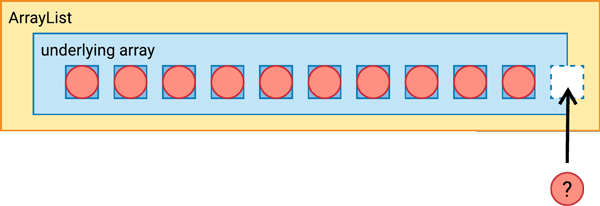
A brand new underlying array is created, 50% larger than the previous size, and the elements are copied over from the old array into the new array.
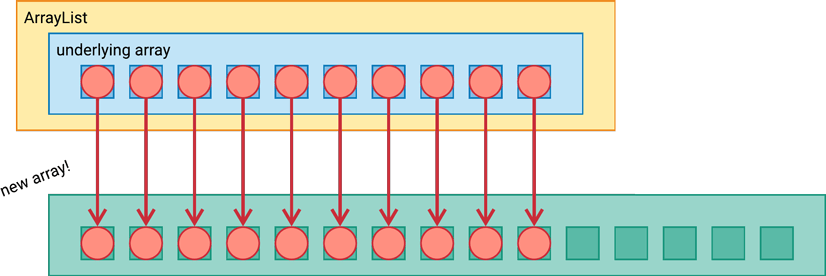
The
ArrayListthen uses this new array instead of the old one. Now there’s a vacancy for that eleventh item, so it’s placed into the array.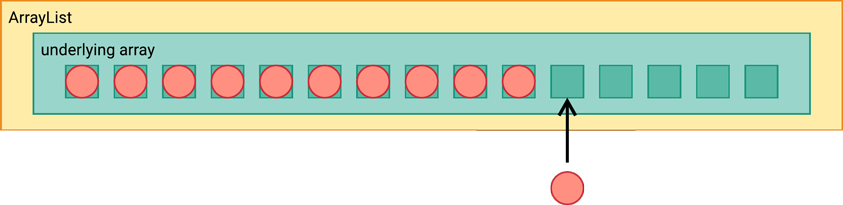
So our same
ArrayListis now backed by an array of size 15. But what happens when we run out of space again, when we have a 16th item that we want to add? Same story - the elements are copied over to a new array that’s 50% bigger. As more and more items are added, the underlying array is replaced with a bigger one, over and over.So how does all of this affect the performance of sequences and collections?
Let’s compare two operation chains:
|
|
(Note that in the collection version, there’s no need to call toList(), because map already returns a List).
The map function is what we might call an isometric collection operation, because the size of the input collection will always be the same as the size of its output collection. When this is the case, the output ArrayList can be created with an initial capacity that equals the size of the input list. And that means the ArrayList will never need to replace its underlying array with a larger array, because it was created with exactly the right size!
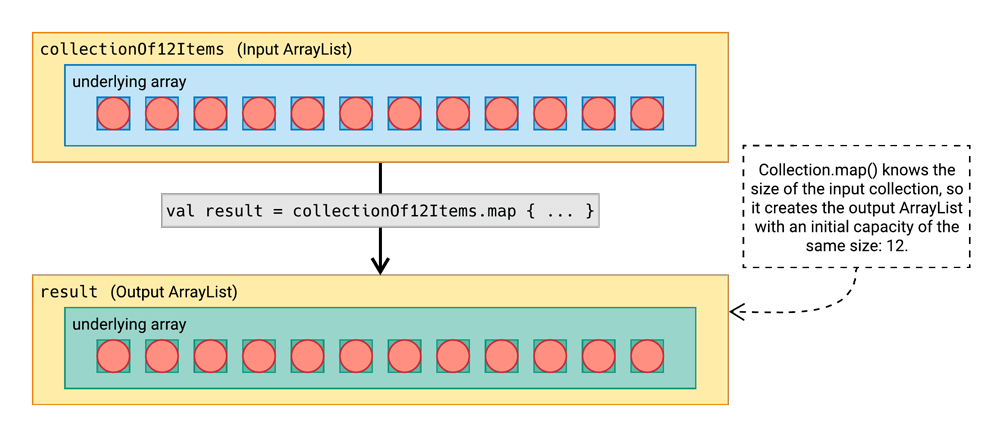
What about the sequence version?
Since sequences are based on iterators, they don’t know how many elements they have. And because they don’t know how many elements they have, they can’t know the correct initial capacity to provide when creating a new ArrayList. So instead, when we call Sequence.toList(), the ArrayList is created with the default initial capacity. So, as more and more items are added to it, that underlying array will get replaced over and over until it’s large enough to hold all of the items.
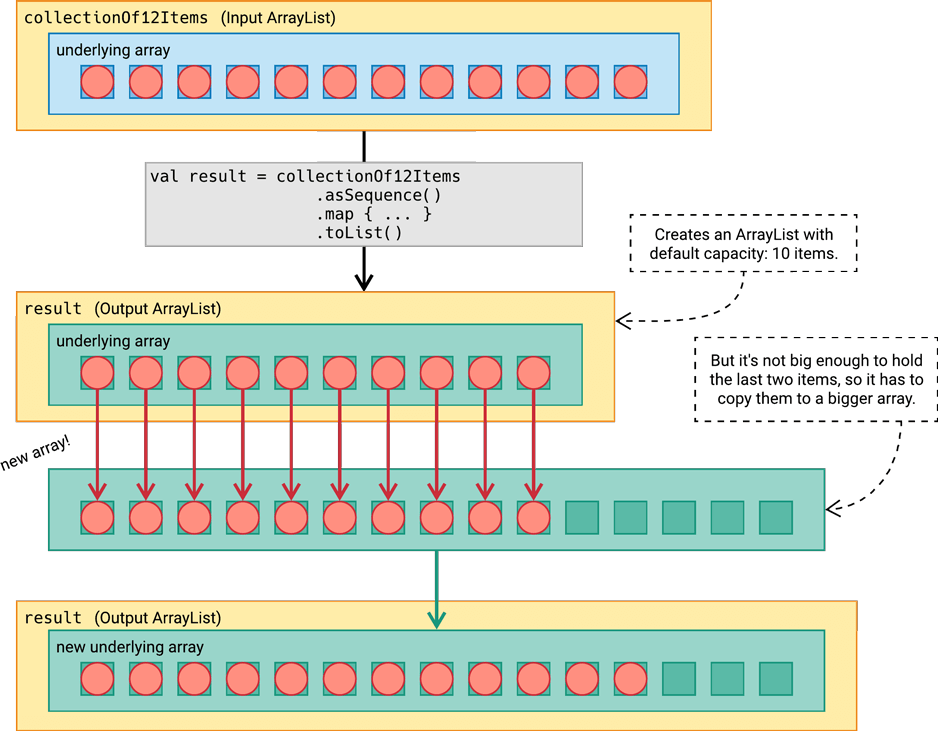
The process of creating a new array and copying the elements can be expensive, and when it’s done enough times, it can really weigh down performance. So collecting the results of an operation chain into a resizable collection like ArrayList can be expensive for sequences, especially when it has many elements.
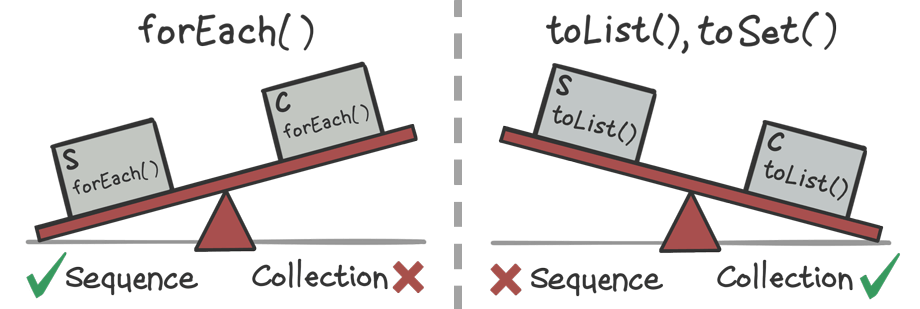
On the other hand, when you’re not collecting the results, sequences don’t take this penalty, so they’re more likely to outperform collections. This means that a terminal like forEach() is especially well-suited to sequences.
These collecting operations aren’t the only ones where resizable collections can hinder the performance of a sequence, though! Certain operations in the middle of a chain can be affected by this too, so let’s take a look at those next.
Stateless and Stateful Operations
Sequences are based on iterators, and iterators can only step forward through its items, one item at a time. So it can come as quite a surprise that sequences also support sorting operations! For example:
val fireSet = BigBoxOfCrayons .asSequence() .filter { it.color in includedColors } .sortedBy { it.color } .map { it.copy(label = "New!") } .take(5) .toSet()If iterators can only step through their items in order, then how is it be possible to change that order part way through the operation chain? How can this function possibly work?
The answer:
- It converts the sequence back into a collection
- It sorts that collection, and then …
- It uses that collection’s iterator as the basis for the sequence operations that follow it.
Here’s the source code for
sorted():public fun <T : Comparable<T>> Sequence<T>.sorted(): Sequence<T> { return object : Sequence<T> { override fun iterator(): Iterator<T> { val sortedList = this@sorted.toMutableList() sortedList.sort() return sortedList.iterator() } } }Copyright 2010-2019 JetBrains s.r.o. and Kotlin Programming Language contributors. | Apache 2 License | SourcePretty clever. Even though
sorted()itself is an intermediate operation, it invokes a terminal operation -toMutableList()- on the inside. You can see how the implementation details here could have a surprising impact, especially in certain cases. For example, if you were to read a 4 GB log file as a sequence and sort it, you’d end up with anArrayListwith 4 GB of data in it, which might be more memory than you allocated to the JVM!A
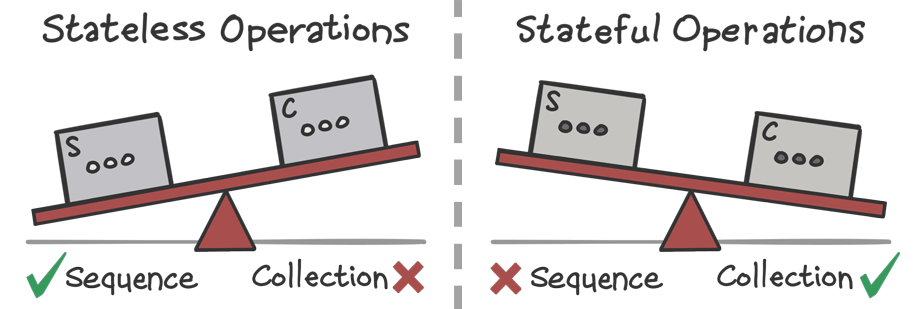
Sequenceclass that does this kind of thing is classified as stateful, meaning that the amount of state it has (and therefore the memory that it needs) can be significant… and the more items are in the sequence, the more state it has!In contrast, a
Sequenceclass that does not need this amount of state is called stateless. Sure, they might have a field or two. But if the amount of state isn’t affected by the size of the sequence, it’s still considered stateless.Most sequence operations are stateless, but there are a few families of operations that are stateful, such as:
- Sorting functions, which use an
ArrayListfor sorting, as we saw above. - Distinct functions, which use a
HashSetto keep track of which elements have been seen.
Because these operations create a resizable collection with a default capacity, they tend to tip the scales back in favor of collections.
Sequences vs. Collections: Other Considerations
Performance isn’t everything. There are other reasons why you might choose one over the other.
Consideration #1: Generators
Besides performance, there are some inherent differences between sequences and collections. Yes, both Sequence and Collection include an iterator() function, but Collection also includes some other properties and functions, such as size, isEmpty(), and contains().
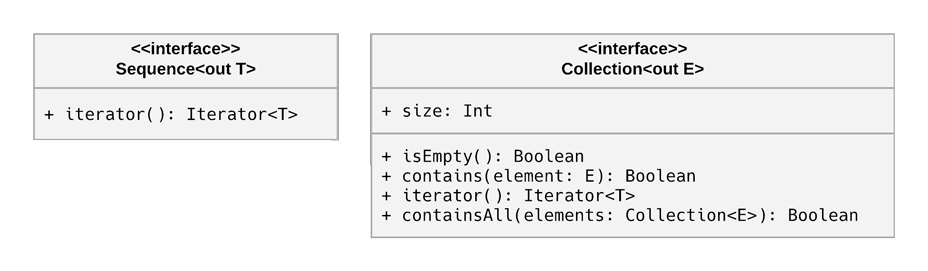
It’s easy to think that “more is better”, and that collections are superior to sequences because of these additional members. But actually, by not including them, sequences are open to more possibilities because they’re less constrained.
For example, sequences don’t have a size property. This means they aren’t constrained to having a size at all. They’re free to have an infinite number of elements.
And in fact, it’s entirely possible to create an infinite sequence. Since a sequence must only support the iterator and its two functions - hasNext() and next() - as long as the next element can be produced at the time that hasNext() or next() is called, it satisfies its interface.
To create an infinite sequence, you can use a sequence generator. A generator is simply a function that’s used to create an element for a sequence as it’s requested.
For example, to create a sequence that produces random integers, you could do this:
val sequence = generateSequence { Random.nextInt() }
Each time that the next() function of this sequence’s underlying iterator is called, the result of Random.nextInt() will be returned. This sequence truly would run forever, so when building out an operation chain, you’ll want to limit it somehow, such as with take(). To print ten random numbers, you could do this:
sequence.take(10).forEach(::println)
Generators aren’t limited to infinite sequences, though! Any time that you want to defer the production of each element until it’s requested, a sequence generator is what you’re looking for. To end a sequence from a generator function, simply return null.
There’s even a fantastic coroutine-based generator that puts the flow control into the generator function instead of the calling code. Pretty neat!
In summary, if you need to generate the values as they’re requested, you’ll want a sequence instead of a collection.
Consideration #2: Available Operations
Collections have more operations than sequences do.
Because sequences are based on iterators, they handle first-to-last operations brilliantly. But there are some collection operations that are processed last-to-first, and many of those are not supported by sequences.
Here are some examples:
| Sequences support… | Sequences do not support… |
|---|---|
fold() |
foldRight() |
reduce() |
reduceRight() |
take() |
takeLast() |
drop() |
dropLast() |
Other limitations include:
- Slicing
- Reversing
- Set theory-ish operations like
union()andintersect() - Many operations that get a single element out of a sequence, such as
getOrNull()orrandom()
If you wanted, you could certainly implement some of these yourself, using the same trick as we saw that the standard library does for sorted(). For example, here’s a function to reverse a sequence:
fun <T> Sequence<T>.reversed() = object : Sequence<T> {
override fun iterator(): Iterator<T> =
this@reversed.toMutableList().also { it.reverse() }.iterator()
}
But this just isn’t natural for sequences, given their first-to-last bias. So in these cases, consider sticking with a collection instead.
Sequences vs. Java Streams
Sequences are similar in spirit to Java Streams. In fact, when they were originally introduced in Kotlin, they were called streams. So when should you choose Kotlin sequences, and when should you choose Java streams?
The Platform
Depending on which platform you’re running on, Java streams might not be available.
- They were introduced in Java 8, so if you’re running on a version of Java older than that, you need to use Kotlin sequences instead.
- On Android, Java stream support began in Android 7.0, so if you’re targeting a minimum version of the OS below that, sequences are your option.
- If you’re developing a Kotlin library, it’d be wise to stick with sequences and other pure Kotlin concepts, because it enables your library to target multiple platforms.
Java Parallel Streams
The biggest selling point for Java streams over Kotlin sequences is that streams can be run in parallel. Sequences do not run in parallel - after all, they are sequential by definition!
Running your operation chains in parallel comes with a startup cost, but once you overcome that cost, it’s generally hard to beat their performance in many cases.
So if you’re on the JVM and you’re processing lots of data with an operation chain that’s amenable to running in parallel, it’d be worth considering Java’s parallel streams.
Summary
Although sequences can perform much better than collections, there are still plenty of cases where collections get the edge. In this article, we looked at the major factors involved when choosing between sequences and collections. Understanding those factors can help us get a better feel for how our operation chains might perform, but ultimately the only way to truly know how things will perform is to measure them - and to do this using a real benchmarking tool like JMH.
And with that, it’s time to invoke a terminal operation on this sequence of articles!
Until next time, happy coding!
Thanks to David Blanc and Dusan Odalovic for reviewing this article, and to Krzysztof Zienkiewicz for reviewing benchmark code.
Share this article: